RAG数据库搭建方法详解|开源代码+完整架构图
项目已开源至:https://github.com/sgsss998/RAG_Memory_System

上一篇基于本地的个人RAG数据库实践:效果不尽如人意写得太情绪化了,技术细节一笔带过,看完只知道我踩了坑、调了参,但到底这套系统是怎么搭起来的,心里没底。这次我换个写法,把这套系统的技术架构、算法原理、模块设计,尽量掰开揉碎地说清楚。顺便说一句,整套代码我已经开源到 GitHub 上了,仓库地址是这个:
https://github.com/sgsss998/RAG_Memory_System
有兴趣的朋友可以直接拉下来看。
核心原理
说人话,这套 RAG 系统最底层的原理就是:
首先,你要先有一个关于自己的数据库,我用的是 obsidian 的vault,里面存放了成千上万个 markdown 格式的文本资料,然后如果你本地修改或者新增 or 删减内容,obsidian 会通过 github 自动同步到云端。
有了数据库之后,你需要让 ai 记住你的数据,并且依据数据帮你分析,这个时候如何让 ai 记住并且理解你的数据?如果每次你都灌输超长上下文给大模型,大模型没一会儿就撑爆了,变得越来越蠢,所以这个时候你就要建立一个基于本地的 rag 检索系统(说白了就是本地向量库,存储着关于你的一切资料),先把你的所有 md 文本通过切片算法转化成向量,储存在一个本地的向量库里,然后大模型每次接收你的提问的时候,就自动把你的提问转化成向量,在向量库里比对有没有相关的数据,有的话就提取出来,作为单次的上下文提示词发给 llm,然后 llm 基于上下文来进行推理,回答你的问题。
这样就可以规避长上下文限制的问题,因为每次llm只是依据检索到的一部分相关数据进行回答。
这就是大的原理框架。避免单次上下文注入太多内容超标,所以先把整个数据库内容切片转化成向量保存在本地,按需索引。这样的好处很明显,那就是理论上你的记忆库可以变得无限大,也不用担心上下文超标的问题。坏处就是极度依赖于你的本地索引质量和你的本地数据质量。比如你提问某个人在某个日期对你说了什么,如果你的本地数据里面有大量的垃圾冗余信息和噪音,比如一大堆的”狗头”表情包,或者”哈哈哈哈哈”之类没有意义的消息,那索引出来的信息肯定很糟糕。
系统架构
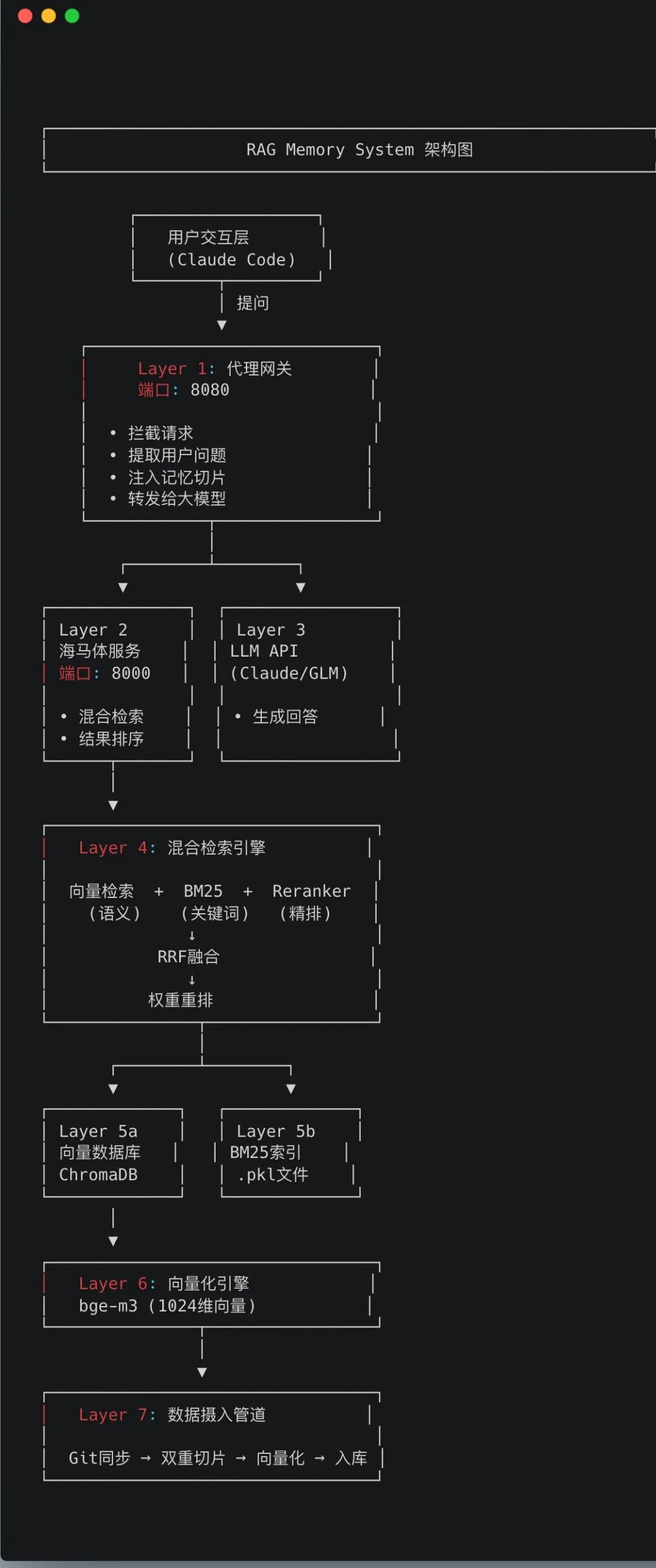
整个系统分六层,像盖楼一样一层一层搭起来的。最顶层是你,你在 MacBook 上用 Claude Code 发问;第二层是一个「翻译官」,跑在 8080 端口,负责拦截你的请求,去记忆库里捞东西,然后把捞到的内容塞进你的问题里,再转发给大模型;第三层是「图书管理员」,跑在 8000 端口,专门负责从数据库里翻书;第四层是「检索引擎」,这是整套系统的核心,把四种检索方式串成一个流水线,后面我会详细说;第五层是「仓库」,向量存在 ChromaDB 里,BM25 索引存在一个 pickle 文件里;最底层是「翻译机」,用 bge-m3 模型把文字变成数字向量。听起来很复杂?其实就是:你问问题 → 系统去库里翻书 → 把翻到的内容塞给 AI → AI 回答你。
混合检索引擎
现在重点来了,那个「检索引擎」是怎么工作的。想象一下你让一个朋友帮你从一堆资料里找东西。如果这个朋友很聪明但眼神不好,他能理解你问的是「投资风险」,但他可能把「风险控制」和「风险管理」都抓出来,因为意思差不多。这就像向量检索:它能理解语义,但对具体的字眼「脸盲」。如果这个朋友眼神好但脑子不太转弯,他只会一个字一个字地匹配,你搜「投资风险」,他真的就只找这四个字连在一起的内容,管你什么语义不语义。这就像 BM25:它不懂你在问什么,但它在字面匹配上极其精准。那最好的方案是什么?让两个朋友分头找,然后把他们的结果拼起来。这就是我做的:向量检索找 20 条,BM25 找 20 条,然后用一个叫 RRF 的算法把两份名单合并,去掉重复的,留下两路都认为重要的那些。
RRF 融合算法
RRF 是什么?我举个例子。假设文档 A 在向量检索里排第 1 名,在 BM25 里排第 3 名;文档 B 在向量检索里排第 5 名,在 BM25 里排第 1 名。RRF 的算法是:给你一个分数,分数 = 1/(60+你的排名)。所以文档 A 的分数 = 1/(60+1) + 1/(60+3) = 0.032,文档 B 的分数 = 1/(60+5) + 1/(60+1) = 0.031。文档 A 赢了,因为它在两路检索里都靠前。这个算法的好处是简单粗暴但有效:如果你在两路检索里表现都不错,你的 RRF 分数就高;如果你只在一路里靠前,另一路根本没你,那你就惨了。合并之后,大概留下 15 条左右的候选文档。
Reranker 精排
到这里还没完。15 条候选文档里,可能有几条是真正相关的,有几条是「凑数」的。怎么办?请一个「法官」来重新打分。这个法官叫 Reranker,它的工作方式是:把你问的问题和每条候选文档拼成一对,然后深度阅读这对内容,判断它们有多相关。和之前的向量检索不同,Reranker 不是把问题变成向量、把文档变成向量然后算距离,而是真的把问题和文档放在一起读,捕捉更细粒度的信号。比如你问「某年某月某日我们聊了什么」,Reranker 能判断出候选文档里的日期是不是你要找的那一天。精排之后,再根据每条文档的「权重」做一个最终排序。权重是怎么来的?后面说。
切片策略
再说说「切片」这件事。你有一篇一万字的笔记,不可能把整篇直接扔给 AI,太长了。所以要先切成小块,每个小块 300 字左右。但怎么切有讲究。我一开始用的是最简单的方法:每 300 字切一刀。结果切出来的东西惨不忍睹,一段话前半截在讲投资,后半截在讲创业,检索的时候两头的语义都被冲淡了。后来我改成「双重语义切片」。第一重,按标题切。如果你的笔记是用 Markdown 写的,有 # ## ### 这些标题,那每个标题下面的内容就是一个天然的语义单元。第二重,在标题切分的基础上,如果某一段还是太长,再用递归的方式微调:优先用段落边界切,不行就用句号切,再不行就用逗号切,实在不行才用空格切,最后才是暴力按字符切。这样切出来的每个小块,语义都比较完整,检索的时候不会被无关内容干扰。
向量化
切好之后,要把每个小块变成「数字」,这样计算机才能理解。这个数字是一个 1024 维的向量,你可以想象成 1024 个坐标,把你这段文字放在一个 1024 维的空间里。意思相近的文字,在这个空间里的位置就靠近;意思不相近的,位置就离得远。怎么把文字变成这个向量?用一个叫 bge-m3 的模型。这个模型是 BAAI 出的,专门做这种「文字变向量」的工作。它有一个好处是中英文都支持,不需要翻译,直接喂中文进去就行。模型通过 Ollama 在本地跑,大小只有 2GB 左右,跑在 M4 Mini 上完全不费劲。每切好一个小块,就扔给 bge-m3,它吐出来一个 1024 维的向量,然后把这个向量连同原文一起存进 ChromaDB。
ChromaDB 向量数据库
ChromaDB 是什么?你可以把它想象成一个「向量仓库」。它存两种东西:一是你的原文,二是原文对应的向量。当你问问题的时候,它先把你的问题也变成向量,然后在仓库里找和问题向量距离最近的那些文档向量,把对应的原文捞出来。怎么找最近?用 HNSW 算法。这个算法有点像快递分拣:先把所有包裹(向量)按「距离」分堆,远的放一堆,近的放一堆,然后在近的那堆里再细分,最后找到你要的那个。好处是快,即使有几百万个向量,查询也能在毫秒级完成。
BM25 索引
BM25 索引是我后来补上的。为什么需要它?因为向量检索对数字、日期、人名「脸盲」。你问「某月 14 号我们聊了什么」,向量检索很可能把 7 号、21 号的内容也捞出来,因为在语义上,它们都是「某月某日」,太像了。BM25 不管语义,它就像疯狗一样做字面匹配:你搜「14」,它就去所有文档里找这个数字,管你什么语义不语义。接上 BM25 之后,再问同样的问题,14 号的文件终于出现在结果里了。
Reranker 配置
Reranker 是最后加上的,也是调优最费劲的部分。bge-reranker-v2-m3 是一个「深度阅读」模型,它不是把问题和文档分别变成向量,而是把问题+文档拼在一起,当成一个整体来读。这样做的好处是精度更高,能捕捉到更细粒度的相关性信号。但代价是慢,每次查询都要实时跑一遍模型推理。我一开始没给它开 GPU 加速,每次查询都要等一分多钟,后来加上 device=‘mps’ 把 M4 的 GPU 跑起来,延迟才降到两三秒。另外还有个坑是候选条数,我一开始没有限制,把 100 条候选塞给 Reranker 去「精读」,内存直接爆了。后来把候选死死限制在 15 条以内,内存才稳住。
权重系统
再说权重系统。这个是我在被噪音折磨了几天之后加上的。我一开始的思路是「数据清洗」,把聊天记录、表情包、废话全部过滤掉,只保留「干货」。结果有一天我问它「某朋友是谁」,它告诉我「知识库未找到相关信息」,我才反应过来,那些被我过滤掉的聊天记录里,其实藏着我想要的人名、事件、关系。后来我就改成了「数据湖」思路:不删任何数据,但给不同来源的数据打上不同的权重。权重是按文件路径自动计算的,比如放在「核心文档」目录下的,权重是 1.0,最高优先级;放在「聊天记录」目录下的,权重是 0.3,保底。检索的时候,Reranker 打完分之后,再乘上一个权重因子,权重高的内容会被优先排到前面。这样所有数据都保留,但高价值内容会自然浮上来,低权重的聊天记录仍然可被搜到,只是不会轻易抢掉核心内容的风头。
Prompt 设计
最后说说 Prompt 设计,这是最容易被忽略、但最关键的一环。我一开始用的 Prompt 是这样的:「请基于以下参考资料回答。如果参考资料中没有,请回答不知道。」结果 AI 变成了「复读机」,只会机械地复述检索结果,完全丧失了推理能力。你问它「老明是谁」,它会翻开聊天记录,找到几条带有「老明」这个名字的消息,然后告诉你「老明的微信号是某某」,但它不敢推理「老明就是你本人」。后来我把 Prompt 改成了更自然的方式:「你是我的赛博外脑。以下是你唤起的记忆切片,就把它们当做你脑子里自然浮现的信息。该推理推理,该回答回答,别老是把「根据知识库」挂在嘴边。」这一改,那个聪明的、有灵性的 AI 瞬间就回来了。它不再把记忆当成外在的参考资料,而是当成了自己潜意识的一部分,自然地推理,自然地调侃。
模块解耦
整套系统的模块之间耦合度其实挺低的。数据源可以是任何文本格式,不一定是 Markdown;切片器可以用 LlamaIndex 或者自己写;向量化引擎可以换成 OpenAI、Voyage、Jina;向量数据库可以换成 Milvus、Qdrant;BM25 索引可以换成 Elasticsearch;Reranker 可以换成 Cohere。海马体服务和代理网关是用 FastAPI 写的,任何语言都可以调用。如果你想自己搭一套,基本上就是:克隆仓库 → 装依赖 → 下模型 → 配置路径 → 建索引 → 启服务,照着 README 来就行,不需要懂太多底层原理。
局限性
最后说说这套系统的局限性。它本质上还是一个检索增强工具,不是什么「全知外脑」。它能帮你从自己的数据里捞东西,但捞出来之后怎么理解、怎么推理,取决于大模型本身的能力和你写的 Prompt。如果你指望它能变成一个真正「懂你」的数字分身,那你大概率会失望,除非你愿意在提示词里给它松绑,并且接受「它只能基于你喂过的数据说话」这件事。我的核心笔记里从来没有用陈述句清清楚楚地写过「我的网站是某某」,所以不管它吞下多少微信碎片聊天,它也拼凑不出这个从未被固化过的事实。数据永远不等于知识,RAG 能给你数据,但它给不了你「理解」。没有大纲,碎片就永远只是碎片;没有骨架,血肉就无法站立。
代码我都开源了,地址再贴一遍:
https://github.com/sgsss998/RAG_Memory_System
里面有完整的 README,包括安装步骤、配置说明、API 文档。如果你想自己搭一套,按照 README 来就行,基本上就是克隆仓库、装依赖、下模型、建索引、启服务这几步。有什么问题可以在 GitHub 上提 issue,我看到会回。这套东西我折腾了大半个月,踩过的坑都在代码里了,希望后来的人能少走一点弯路。